微服务架构,每个服务功能内聚,独立开发部署和运维,服务间通过接口通信,相比单体架构,开发,部署,扩展,迭代处理更加简单灵活。
但是,随着为服务的增多,服务间的依赖关系更加复杂。这是如果单个服务发生故障,有可能导致故障沿着调用链路,扩散至多个上游服务,进而导致多个业务链路故障。
故障的发生难以避免,但故障的级联可以避免。微服务之间适当做解耦,可以规避级联故障的发生。
级联故障
级联故障是指一个服务的故障,触发了其他服务的故障。
超时
网络超时
网络调用问问需要阻塞等待响应(IO多路复用相当于单个线程阻塞等待多个链接的事件)。网络环境和下游服务都有可能发生各种异常,导致无响应活慢响应。这对调用方意味着线程阻塞,资源长时间无法释放,进而导致新的请求获取不到相应资源,从到导致本服务异常,故障级联。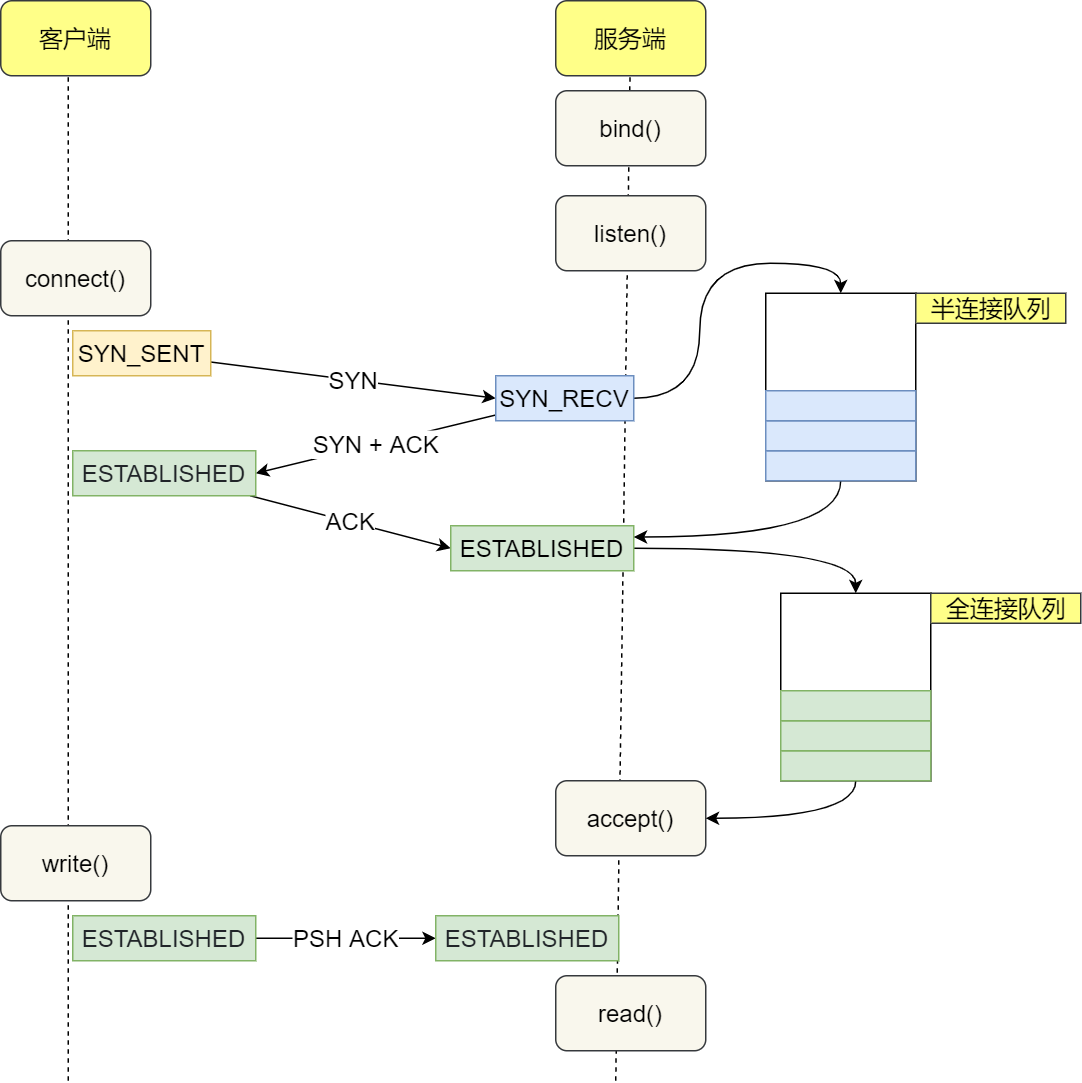
- TCP 连接过程中,服务可能负载过高,无暇处理半连接队列。Linux默认的TCP连接超时时间为127秒。
- 客户端调用write()发送请求,如果服务器宕机没有返回ACK,则客户端会开始TCP重传,默认15次重传,约20~30分钟。该过程write始终阻塞
- 客户端发送请求后,调用read()等待响应。如果服务端故障没有响应,则客户端默认无限等待。
所以,所有网络请求,包括建立连接和网络读写,都需要配置超时时间。
需要注意的是,Golang的net/http的DefaultClient默认是没有超时配置的。
当没有初始化http.Client, 使用http.Get或者http.Post执行请求时,默认使用DefaultClient,而DefaultClient=&Client{}, 没有连接超时和读写超时配置。这是危险的,不要在生产环境使用。参见这篇文章
正确的做法是,初始化自己的http client,配置合理超时
1 | import "net/http" |
连接池&线程池超时
为了避免重复创建连接的开销,往往使用连接池来管理和复用连接。从设置最大连接数量限制的连接池中获取连接,也需要有超时配置。
- 若无超时配置,当服务压力活下游响应慢时,单位时间内,释放的连接少,而新增的等待获取连接的线程多,服务出现故障。
- 如果配置了超时时间,则获取不到连接的请求获取连接超时,快速失败,避免整体故障。
Golang mysql并没有连接池超时的配置项,而是通过context来判断连接池超时。
下面database/sql代码,当前连接数>最大连接数时,便会阻塞等待释放,或者context超时。如果传入的context没有配置超时,则会无限制等待连接被释放。
1 | // conn returns a newly-opened or cached *driverConn. |
获取连接超时错误,比起阻塞等待连接,服务可用性更高。
熔断
熔断的作用是:
- 减少下游压力。如果下游服务过载,熔断机制降低了对下游的访问量,能给下游喘息的机会。
- 快速失败,减少上游资源,避免下游故障级联到上游。
- 如果调用下游大比例失败,则不用浪费资源反复调用
- 如果下游响应慢,请求超时,可以避免资源在等待超时期间的锁定和浪费。熔断和超时产生协同作用。快速失败的资源节省效果明显,避免上游资源浪费在超时的等待。而且超时的时候,上游往往进行重试,进一步增加下游的压力。熔断避免了故障时额外的重试压力,而且不影响常规的重试。
限制下游返回
当下游服务返回不符合预期是,比如响应体过大,会引发上游服务雪崩。上游服务需要对下游返回做严格校验,以保护自身不被拖垮。尤其是上游服务是流量汇聚点时。
限流
超时,熔断和限制下游返回都是上游视角,针对下游无响应,慢响应,响应异常的情况,保护自身,以免被级联。
限流和过载保护则是下游服务对自身处理能力的限制和保护,既保护自己不雪崩,也避免慢响应影响上游。
过载保护,就是在系统负载超过系统最大处理能力时,主动拒绝流量,以保持最大处理能力,避免雪崩。这也是一种fail fast的思想。高负载下的慢响应,比返回错误糟糕。Fail Fast允许调用系统快速完成对任务的处理,这最终是成功还是失败取决于应用程序逻辑,而慢响应会长时间占用系统和被调用系统的资源。
限流工具,可以分为入口限流和出口限流,又可以分为固定预支限流和自适应动态限流。
总结
- 快速失败思想: 超时,熔断,限流,过载,丢弃过大响应都是快速失败思想的具体时间。分布式系统中,延迟是致命的,慢响应的系统比快速失败的系统更难处理。